The Fit Method#
Introduction#
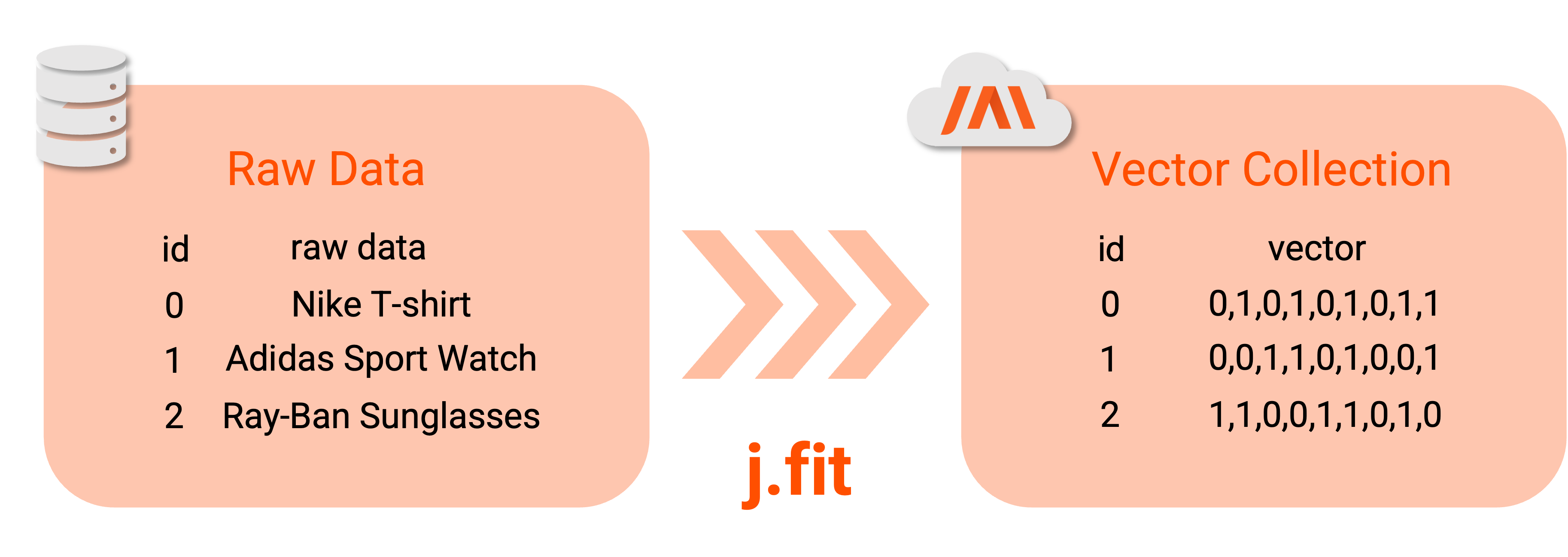
To start setting your dataset, you first need to add and fit it to your JAI environment.
Using the j.fit method is the better way to achieve this.
This method adds your raw data to your JAI environment, trains the data based on the chosen model type,
and stores your model’s latent vector representation in a collection.
Note
A collection is an effective way to store vectors that permits a fast similarity search between these vectors.
Note
Latent vectors are created when training some model in a neural network (NN) and don’t directly correlate with the data passed by the NN. They are just part of your trained model that helps to define a correct output when we need to predict something on this model.
The fit method allows training on different types of data, such as Tabular, Text and Image. Here is the list of models that JAI supports:
Tabular data: supervised and self-supervised models
Text data: NLP Transformers models, FastText and Edit Distance Language model
Image data: JAI works with all torchvision image models.
The sections below show more information about using these models in JAI. For the complete reference of the fit method, look at API reference.
Important
JAI deletes all raw data you sent some time after running j.fit, keeping internally only with the latent vector
representation of your training data.
Basics#
The j.fit method has three main parameters: name, data and db_type:
>>> j.fit(
... name='Collection_name',
... data=data,
... db_type='SelfSupervised'
... )
The
nameparameter is the name you will give for the data you are fitting. It must be a string with a maximum of 32 characters.datais the data that you want to fit. It must be apandas.DataFrameor apandas.Series. For using image data, the images first have to be encoded to, after, being inserted to fit, as shown in Fitting Image data.db_typeis the parameter that defines what type of training will be realized by the fit method. The possible values are'Supervised','SelfSupervised','Text','FastText','TextEdit'and'Image'. Each of these has its own set of parameters and hyperparameters. For more information about them, check Fitting Tabular data, Fitting Text data, and Fitting Image data.overwriteis used when you want to overwrite an already existent collection in your JAI environment. Default value isFalse.
JAI uses your data index to perform a lot of methods internally. You can define the index of your data in two ways:
using the pandas’ index or creating a column named 'id'.
When you don’t make an 'id' column, JAI automatically considers your data pandas’ index;
on the other hand, JAI uses your 'id' column as your data index. So, take care with duplicated values.
Tip
As a JAI good practice, try always to use Pandas native index:
It avoids the possibility of having more than one data index.
It enables the native usage of
.loccommands, making using JAI responses easier.
Fitting Tabular Data#
Overview#
JAI provides two different ways to fit your tabular data: Supervised and SelfSupervised.
SelfSupervised training doesn’t need labels in your data.
It tries to learn only by observing the relationship among your data columns, creating data embeddings at the end of the train.
One can use these embeddings as pre-trained data for Supervised learning or, also, for performing similarity search among them.
Note
An embedding is a low-dimensional, learned continuous vector representation of discrete variables. In other words, JAI is transforming your data into some vectors whose most similar ones are closer than dissimilar ones.
Supervised training needs labels to make the model learn. It can be categorized into two types of takes: Classification or
Regression. Classification tasks occur when the data label is a category, while Regression tasks occur when the model needs
to predict continuous values. JAI supports both tasks types of supervised learning.
There are some important parameters in j.fit that can improve your model:
'split': It defines how JAI will split the data for train and test.'pretrained_bases': This parameter is used when you want to enrich your current train with another already JAI fitted collection in your environment.'hyperparameters': It describes the hyperparameters of the chosen model training.'label'(Supervised): Parameter used to define the label column of your supervised data and what type of task it will perform.
You can check a complete reference of these parameters in API reference.
A complete exampĺe of fitting tabular data is shown below:
>>> from jai import Jai
>>> from sklearn.datasets import fetch_california_housing
...
>>> # Jai class initialization
>>> j = Jai()
...
>>> # Load test dataset.
>>> data, labels = fetch_california_housing(as_frame=True, return_X_y=True)
...
>>> # Fitting a SelfSupervised collection.
>>> # The embeddings created by this fit will be used for training
>>> # a Supervised collection afterwards.
>>> j.fit(
... name="california_selfsupervised",
... data=data,
... db_type="SelfSupervised",
... split={"type": "random", "test_size": 0.2},
... hyperparams={"learning_rate": 3e-4, "pretraining_ratio": 0.8},
... )
...
>>> # Getting only the label column and renaming it.
>>> data_sup = labels.reset_index().rename(columns={"index": "id_house"})
...
>>> # Fitting a supervised collection using the previous fitted self-supervised collection.
>>> # The 'pretrained_bases' merges the data_sup with the 'california_selfsupervised' by
>>> # the 'id_name' and uses the merged dataframe to create the supervised fit.
>>> j.fit(
... name="california_regression",
... data=data_sup,
... db_type="Supervised",
... pretrained_bases=[
... {"db_parent": "california_selfsupervised", "id_name": "id_house"}
... ],
... label={"task": "regression", "label_name": "MedHouseVal"},
... )
Hyperparameters#
There are a lot of possible combinations of hyperparameters for tabular fit.
Because of it, this subsection shows some of the primary hyperparameters for your train in JAI, but feel free to test all
hyperparameters when using j.fit and have fun fitting your models with JAI.
Some of the most notable hyperparameters for tabular training are the following:
For a self-supervised model:
'min_epochs': Defines how much will be the minimum epoch value for your model training. The recommended value is'min_epochs' >= 500.'max_epochs': Defines how much will be the maximum epoch value for your model training. The recommended value is'max_epochs' == 'min_epochs'.'pretraining_ratio': Specifies the value of the rate of feature masking on the self-supervised train. Feature masking is a NN way to minimize overfitting and improve model training.'batch_size':Batch size for training. Depending on the value chosen, it can decrease the training time.
For a supervised model:
All hyperparameters listed for self-supervised training
'decoder_layer': Chooses the decoder layer type of the NN. It’s recommended to use'2L_BN'(Two linear batch normalization layers) for supervised regression training.
To obtain all information about hyperparameters, check Fit Kwargs.
Supervised Tasks#
JAI supports two different types of tasks for each Classification and Regression.
For Classification, JAI provides 'classification' and 'metric_classification',
while for Regression it provides 'regression' and 'quantile_regression'.
classification: JAI trains the model to learn how to classify the classes by usingCrossEntropyLossas the loss function and making predictions by getting theargmaxof probabilities of each category in the model.metric_classification: It trains the model using contrastive learning. It trains the model using contrastive learning. Training this way makes the decision margin more robust, even with imbalanced datasets.regression: It performs regression, predicting only a result for each input row.quantile_regression: It trains a quantile regression, predicting the most probable value and the chosen confidence interval values.
Fitting Text Data (NLP)#
For any uses of text-type data, data can be a list of strings, pandas.Series` or pandas.DataFrame.
If data is a list, then the ids of your collection will be set with
range(len(data_list)).If data is a
pandas.Seriesorpandas.DataFrame, the ids will be defined as explained in Basics.
Using FastText#
fastText is an extension of the word2vec model for word embedding. It doesn’t learn vector for words directly, but it represents each word as an n-gram of characters. Therefore, this method captures the meaning of shorter words, besides understanding prefixes and suffixes.
>>> from jai import Jai
...
>>> # Jai class initialization
>>> j = Jai()
...
>>> # Generating a list of words
>>> data = [
... "flock",
... "gene",
... "background",
... "reporter",
... "notion",
... "rocket",
... "formation",
... "athlete",
... "suitcase",
... "sword",
... ]
...
>>> # Fitting with fastText
>>> name = 'fastText_example'
>>> j.fit(name, data, db_type='FastText')
Using Transformers#
For using Transformers, just set db_type="Text".
The model used by default is the pre-trained BERT. For more information about Transformers,
consider visiting the Hugging Face page.
>>> from jai import Jai
...
>>> # Jai class initialization
>>> j = Jai()
...
>>> # Generating a list of words
>>> data = [
... "flock",
... "gene",
... "background",
... "reporter",
... "notion",
... "rocket",
... "formation",
... "athlete",
... "suitcase",
... "sword",
... ]
...
>>> # Fitting with Transformers
>>> name = 'BERT_example'
>>> j.fit(name, data, db_type='Text')
For using another Transformer model, specify the 'hyperparams' parameter as shown below:
>>> j.fit(name, data, db_type='Text', hyperparams={'nlp_model': CHOSEN_MODEL})
Using Edit Distance Model#
The Edit distance model quantifies the difference between two strings by counting the minimum number of operations to transform one string into the other using Levenshtein distance.
You can use this by defining db_type=TextEdit in your j.fit as below:
>>> from jai import Jai
...
>>> # Jai class initialization
>>> j = Jai()
...
>>> # Generating a list of words
>>> data = [
... "flock",
... "gene",
... "background",
... "reporter",
... "notion",
... "rocket",
... "formation",
... "athlete",
... "suitcase",
... "sword",
... ]
...
>>> # Fitting with text edit
>>> name = 'TextEdit_example'
>>> j.fit(name, data, db_type='TextEdit')
Fitting Image Data#
JAI can also fit image data, but you must encode all image data before being added to your JAI environment.
To make this, one can use the base64 python package, as shown below:
>>> with open(filename, "rb") as image_file:
>>> encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
JAI provides an auxiliary method to help you to add your images into your environment.
The read_image_folder read a specified images local folder and returns them as an encoded pandas.Series format.
>>> from jai.image import read_image_folder
>>> image_data = read_image_folder('your_local_image_folder_path')
Another proper JAI auxiliary method for image data fitting is the resize_image_folder.
Resizing images before inserting is recommended because it reduces writing, reading and processing time during model inference,
besides minimising the probability of crashing your fitting.
>>> from jai.image import resize_image_folder
>>> resize_image_folder('your_local_image_folder_path')
For fitting Image data, just define db_type=’Image’ when using ‘j.fit’. JAI permits using some of Torchvision pre-trained models
to fit your data. The default image model in JAI is 'vgg16'. To get the list of acceptable models, check
API reference.
>>> import pandas as pd
...
>>> from jai import Jai
>>> from jai.image import read_image_folder
>>> from jai.image import resize_image_folder
...
>>> IMAGE_FOLDER = 'your_local_image_folder_path'
...
>>> # Jai class initialization
>>> j = Jai()
...
>>> # Resizing images
>>> resize_image_folder(IMAGE_FOLDER)
...
>>> # Reading images
>>> data = read_image_folder(IMAGE_FOLDER)
...
>>> # Fitting data
>>> name = 'Image_example'
>>> j.fit(name, data, db_type='Image')
To change the image model, add the hyperparams parameters, as shown below:
>>> j.fit(name, data, db_type='Image', hyperparams={'model_name': 'Desired_model'})