US Census Classification#
What are we going to do?#
In this quick demo, we will use JAI to:
Train and deploy models into a secure and scalable production-ready environment.
Complete a classification task - Predict whether household income exceeds $50K/yr based on census data
Importing libraries#
[1]:
from jai import Jai
import pandas as pd
JAI Auth Key#
If you don’t already have an auth key, you can get your auth key here - free forever. Also, please make sure to check your spam folder if you can’t find it in your inbox!
[ ]:
from jai import get_auth_key
get_auth_key(email = 'email@emailnet.com', firstName = 'JAI', lastName = 'Z')
<Response [201]>
Dataset quick look#
This dataset contains data collected by the 1994 U.S. Census. It contains personal information such as education, marital status, occupation and sex and in this example we will use that data to predict whether an individual is making more or less that 50k dollars per year.
[2]:
df = pd.read_csv('https://myceliademo.blob.core.windows.net/census-us/adult.csv?sv=2020-04-08&st=2021-05-17T18%3A19%3A59Z&se=2025-01-18T18%3A19%3A00Z&sr=b&sp=r&sig=sH%2B2Za%2FTuXsatqgmRX3eG%2FQfZTh1M2ptMUi8NTXBXF4%3D')
df = df.reset_index().rename(columns={'index':'id'})
[3]:
# Show name of columns and non-null count
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32561 entries, 0 to 32560
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 32561 non-null int64
1 age 32561 non-null int64
2 workclass 32561 non-null object
3 fnlwgt 32561 non-null int64
4 education 32561 non-null object
5 education.num 32561 non-null int64
6 marital.status 32561 non-null object
7 occupation 32561 non-null object
8 relationship 32561 non-null object
9 race 32561 non-null object
10 sex 32561 non-null object
11 capital.gain 32561 non-null int64
12 capital.loss 32561 non-null int64
13 hours.per.week 32561 non-null int64
14 native.country 32561 non-null object
15 income 32561 non-null object
dtypes: int64(7), object(9)
memory usage: 4.0+ MB
[4]:
# Show first 5 lines of dataframe
df.head()
[4]:
| id | age | workclass | fnlwgt | education | education.num | marital.status | occupation | relationship | race | sex | capital.gain | capital.loss | hours.per.week | native.country | income | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 90 | ? | 77053 | HS-grad | 9 | Widowed | ? | Not-in-family | White | Female | 0 | 4356 | 40 | United-States | <=50K |
| 1 | 1 | 82 | Private | 132870 | HS-grad | 9 | Widowed | Exec-managerial | Not-in-family | White | Female | 0 | 4356 | 18 | United-States | <=50K |
| 2 | 2 | 66 | ? | 186061 | Some-college | 10 | Widowed | ? | Unmarried | Black | Female | 0 | 4356 | 40 | United-States | <=50K |
| 3 | 3 | 54 | Private | 140359 | 7th-8th | 4 | Divorced | Machine-op-inspct | Unmarried | White | Female | 0 | 3900 | 40 | United-States | <=50K |
| 4 | 4 | 41 | Private | 264663 | Some-college | 10 | Separated | Prof-specialty | Own-child | White | Female | 0 | 3900 | 40 | United-States | <=50K |
Inserting data into Jai#
To be able to use Jai’s functionalities, we first need to turn the data into a Jai collection. The method used to send data to Jai is j.setup (or j.fit; they are the same), which can then be consumed through the methods j.similar and j.predict. By using the setup method you add your raw data to your JAI environment, use the data to train your model based on the chosen model type and your model’s latent vector representation is then stored in the Jai collection.
[5]:
# Instantiate Jai class
j = Jai()
ans = j.setup(
# Name of Jai collection
name = 'census',
# verbose = 2 shows loss graph at the end of the setup
verbose = 2,
# data to be inserted into Jai - a pandas dataframe is expected
data = df,
db_type = 'Supervised', #Text, FastText, TextEdit, Image, Supervised, Selfsupervised
label = {'task':'classification', 'label_name':'income'}, #classification, metric_classification, regression, quantile_regression
split = {'type':'stratified', 'split_column':'income', 'test_size':0.1},
overwrite = True
)
Insert Data: 100%|██████████| 2/2 [00:01<00:00, 1.07it/s]
Training might finish early due to early stopping criteria.
Recognized setup args:
- db_type: Supervised
- label:
* task : classification
* label_name : income
* regression_scaler: None
* quantiles : []
JAI is working: 100%|██████████|22/22 [00:36]
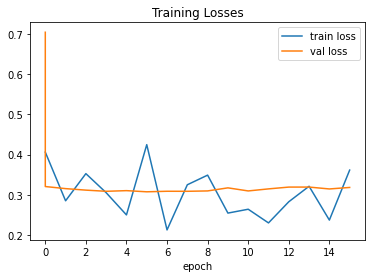
Setup Report:
Metrics classification:
precision recall f1-score support
<=50K 0.88 0.94 0.91 4976
>50K 0.75 0.58 0.65 1536
accuracy 0.86 6512
macro avg 0.82 0.76 0.78 6512
weighted avg 0.85 0.86 0.85 6512
Best model at epoch: 05 val_loss: 0.31
Model Inference#
We can use the trained model to make inferences on any specific index or in other added new data
[6]:
j.predict('census',
data = df.tail(1).drop('income',axis = 1),
# predict_proba = True shows the probability that the item belongs to each class
predict_proba = True)
Predict: 100%|██████████| 1/1 [00:00<00:00, 4.16it/s]
[6]:
[{'id': 32560,
'predict': {'<=50K': 0.9997827410697937, '>50K': 0.0002172834356315434}}]
[7]:
j.predict('census',
data = df.head().drop('income',axis = 1),
# predict_proba = True shows the probability that the item belongs to each class
predict_proba = True)
Predict: 100%|██████████| 1/1 [00:00<00:00, 3.79it/s]
[7]:
[{'id': 0,
'predict': {'<=50K': 0.9080128073692322, '>50K': 0.09198720753192902}},
{'id': 1,
'predict': {'<=50K': 0.7557201981544495, '>50K': 0.24427981674671173}},
{'id': 2,
'predict': {'<=50K': 0.7873145937919617, '>50K': 0.21268539130687714}},
{'id': 3,
'predict': {'<=50K': 0.9710868000984192, '>50K': 0.02891319803893566}},
{'id': 4,
'predict': {'<=50K': 0.725451648235321, '>50K': 0.27454838156700134}}]
Requests via Rest API#
[8]:
body = df.head().drop('income',axis=1).to_dict(orient='records')
body
[8]:
[{'id': 0,
'age': 90,
'workclass': '?',
'fnlwgt': 77053,
'education': 'HS-grad',
'education.num': 9,
'marital.status': 'Widowed',
'occupation': '?',
'relationship': 'Not-in-family',
'race': 'White',
'sex': 'Female',
'capital.gain': 0,
'capital.loss': 4356,
'hours.per.week': 40,
'native.country': 'United-States'},
{'id': 1,
'age': 82,
'workclass': 'Private',
'fnlwgt': 132870,
'education': 'HS-grad',
'education.num': 9,
'marital.status': 'Widowed',
'occupation': 'Exec-managerial',
'relationship': 'Not-in-family',
'race': 'White',
'sex': 'Female',
'capital.gain': 0,
'capital.loss': 4356,
'hours.per.week': 18,
'native.country': 'United-States'},
{'id': 2,
'age': 66,
'workclass': '?',
'fnlwgt': 186061,
'education': 'Some-college',
'education.num': 10,
'marital.status': 'Widowed',
'occupation': '?',
'relationship': 'Unmarried',
'race': 'Black',
'sex': 'Female',
'capital.gain': 0,
'capital.loss': 4356,
'hours.per.week': 40,
'native.country': 'United-States'},
{'id': 3,
'age': 54,
'workclass': 'Private',
'fnlwgt': 140359,
'education': '7th-8th',
'education.num': 4,
'marital.status': 'Divorced',
'occupation': 'Machine-op-inspct',
'relationship': 'Unmarried',
'race': 'White',
'sex': 'Female',
'capital.gain': 0,
'capital.loss': 3900,
'hours.per.week': 40,
'native.country': 'United-States'},
{'id': 4,
'age': 41,
'workclass': 'Private',
'fnlwgt': 264663,
'education': 'Some-college',
'education.num': 10,
'marital.status': 'Separated',
'occupation': 'Prof-specialty',
'relationship': 'Own-child',
'race': 'White',
'sex': 'Female',
'capital.gain': 0,
'capital.loss': 3900,
'hours.per.week': 40,
'native.country': 'United-States'}]
[ ]:
import requests
header={'Auth': 'INSERT_YOUR_AUTH_KEY_HERE'}
url_predict = f"https://mycelia.azure-api.net/predict/census?predict_proba=True"
ans = requests.put(url_predict, json=body, headers=header)
ans.json()
[{'id': 0,
'predict': {'<=50K': 0.9708954095840454, '>50K': 0.0291045643389225}},
{'id': 1,
'predict': {'<=50K': 0.9445657134056091, '>50K': 0.05543423444032669}},
{'id': 2,
'predict': {'<=50K': 0.7718135714530945, '>50K': 0.22818641364574432}},
{'id': 3,
'predict': {'<=50K': 0.9780237078666687, '>50K': 0.021976308897137642}},
{'id': 4,
'predict': {'<=50K': 0.6955583095550537, '>50K': 0.3044416606426239}}]